



Unsupervised Learning Explained: The Simple Guide to Clustering with Python
Learn how unsupervised learning works with easy examples of K-Means and Hierarchical Clustering. Perfect for beginners looking to master machine learning step by step.

We’ve covered a lot in our ongoing Machine Learning series. Not only have I learned a lot in the process but I am hopeful that you guys have also been learning a lot too!
Machine Learning is such a big topic so breaking it down to bite sized chunks helps. That’s the deal with anything in life, but maybe even more so in programming. Take a big task and break it into many little tasks. Baby steps are the fastest way to build your skills and create a strong foundation along the way.
We’ve covered a lot surrounding supervised learning but there is a whole other realm in the Machine Learning sphere, the other sphere being unsupervised learning. What is this and when do we prefer using unsupervised learning techniques?
In this article I’ll inch into the world of unsupervised learning but focus on the first phase. We will cover what unsupervised learning is and go through Clustering, probably the most popular form of this type of learning.
Each week, I dive deep into Python and beyond, breaking it down into bite-sized pieces. While everyone else gets just a taste, my premium readers get the whole feast! Don't miss out on the full experience – join us today!
My goal here is to give you guys an understanding of this type of learning so you can see how different it is from the former, supervised learning. We will go through some real world code using a simple but straightforward example to break it all down.
This article is only a slither of my Machine Learning series. If you are interested in taking your skills to new heights and learning ML to use in your career check out our Machine Learning series here.
For my weekly free articles I try to spend some time mixing up the introduction for you guys, but as many of you know the actual content from these articles are segments from my weekly long-form articles.
These are mean’t to be a stepping stone but also a taste of my premium content. I always link the full article at the bottom for you. The long form articles go into more detail, have more code examples and tips you can use to take action today.
If you haven’t subscribed to my premium content yet, you should definitely check it out. You unlock exclusive access to all of these articles and all the code that comes with them, so you can follow along!
Plus, you’ll get access to so much more, like monthly Python projects, in-depth weekly articles, the '3 Randoms' series, and my complete archive!
I spend a lot of my week on these articles, so if you find it valuable, consider joining premium. It really helps me keep going and lets me know you’re getting something out of my work!
👉 Thank you for allowing me to do work that I find meaningful. This is my full-time job so I hope you will support my work.
If you’re already a premium reader, thank you from the bottom of my heart! You can leave feedback and recommend topics and projects at the bottom of all my articles.
👉 If you get value from this article, please help me out, leave it a ❤️, and share it with others who would enjoy this. Thank you so much!
What is Unsupervised Learning?
Unsupervised learning is a type of machine learning where the algorithm works with data that doesn’t have any labels. Instead of trying to predict what a label should be, it looks for patterns, structures, or connections in the data.
Do any of you guys remember Blockbuster? Well, maybe you don’t... It was basically the greatest place of all time, well before Redbox and Netflix. A store where you could rent movies and games.
Let’s take Blockbuster and say the movies aren’t labeled, but you can still sort them based on things like themes, acting styles, or cover designs.
In the same way, unsupervised learning groups or simplifies data based on its natural similarities. There are two main types of unsupervised learning:
Clustering: This is about grouping data points that are similar to each other.
Dimensionality Reduction: This reduces the number of features in the data while keeping the important information.
Let’s begin with the first form of unsupervised learning, which is clustering.
Understanding Clustering: Grouping Similar Data Points
Clustering is a key method in unsupervised learning that focuses on grouping data points that are alike in some way. Unlike classification, where you already know the labels, clustering finds patterns without any prior knowledge of the data.
It’s commonly used in areas like customer segmentation, detecting unusual behavior, and sorting documents.
Let’s say a business wants to better understand its customers. Without any preset categories, the company might look at customer buying patterns and group people based on similar habits. This helps them create targeted marketing campaigns, offer personalized recommendations, and provide better customer service.
👉 If you get value from this article, please help me out, leave it a ❤️, and share it with others who would enjoy this. Thank you so much!
K-Means Clustering: The Workhorse of Clustering Algorithms
K-Means is one of the most popular clustering algorithms because it's simple and works efficiently. It groups data into K clusters, with each data point assigned to the nearest cluster center. The algorithm keeps updating these centers to make sure points in the same group are as close to each other as possible.
The process starts by picking K random points to act as the initial cluster centers. Then, each data point is assigned to the nearest cluster center based on a distance measure, usually Euclidean distance.
After all the points are assigned, the centers are recalculated by averaging all the points in each cluster. This process repeats until the cluster assignments stay the same or the algorithm runs for a set number of steps.
If I break these down into steps for you then here’s how the K-Means algorithm works:
Pick K initial centroids randomly.
Assign each data point to the nearest centroid.
Update the centroids based on the mean of the points assigned to each cluster.
Repeat steps 2 and 3 until the centroids stop changing.
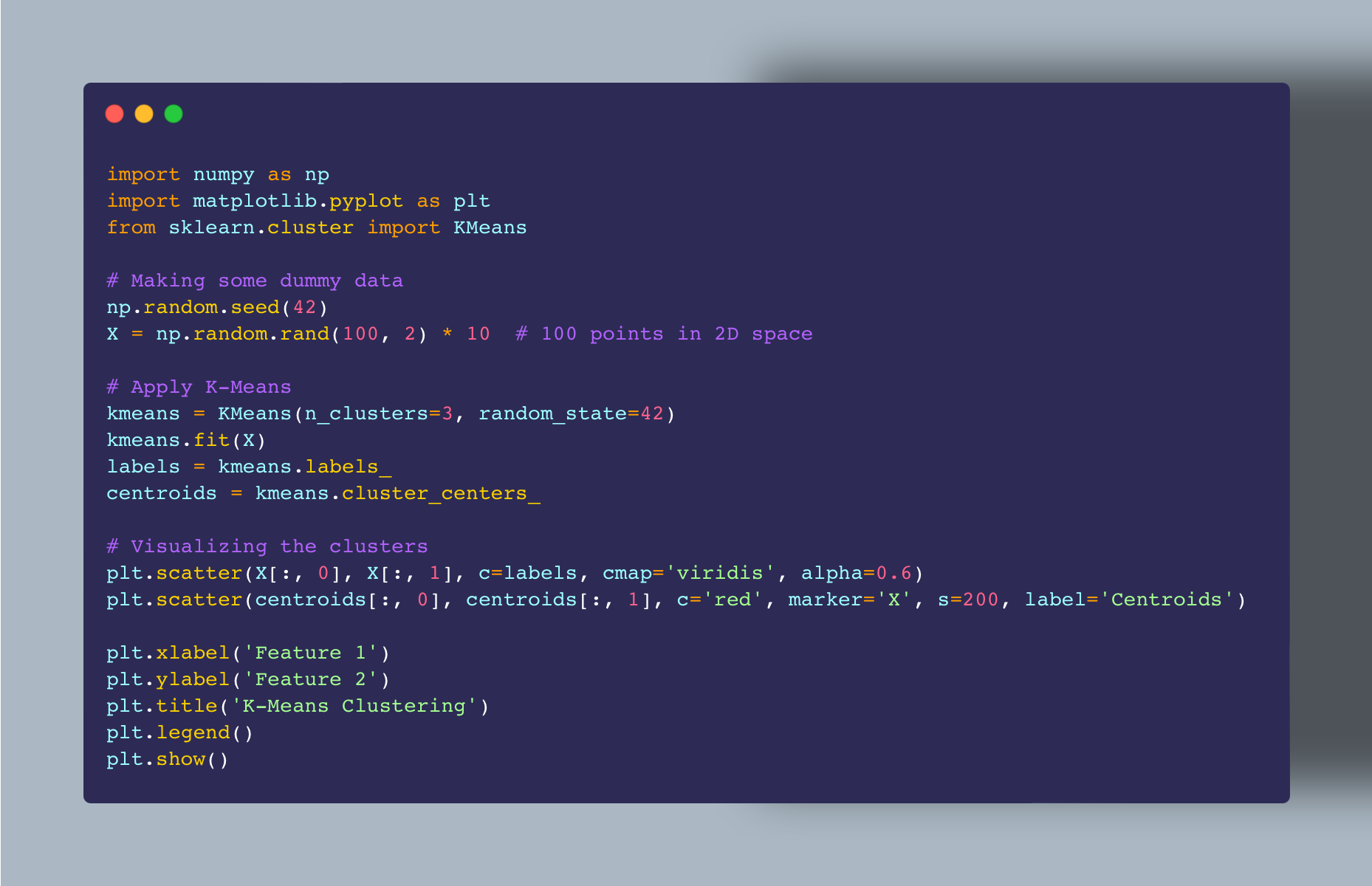
This code block creates random data points and applies K-Means to sort them into three clusters. The resulting plot shows how the data points are grouped, with the cluster centers marked in red.
One challenge with K-Means is figuring out the right number of clusters, K. To help with this, the Elbow Method is commonly used. This method plots the within-cluster sum of squares (WCSS) for different values of K.
The best K is usually where the graph shows an "elbow," meaning adding more clusters doesn’t significantly improve the results.
Stop Struggling—Master Python the Fast & Easy Way!
Most people waste months bouncing between tutorials and still feel lost. That won’t happen to you.
👉 I’m giving you my exact system that’s been proven and tested by over 1,500 students.
My Python Masterclass gives you a clear roadmap, hands-on practice, and expert support—so you can master Python faster and with confidence.
Here’s What You Get:
✅ 135+ step-by-step lessons that make learning easy
✅ Live Q&A & 1-on-1 coaching (limited spots!)
✅ A private community so you’re never stuck
✅ Interactive tests & study guides to keep you on track
No more wasted time. No more confusion. Just real progress.
Enrollment is open—secure your spot today!
P.S - Save over 20% with the Code: PremiumNerd20
Hierarchical Clustering
Hierarchical clustering is different from K-Means because you don’t need to decide how many clusters you want upfront. Instead, it builds a tree-like structure called a dendrogram, which helps you figure out the right number of clusters. There are two main types: agglomerative (bottom-up) and divisive (top-down).
Agglomerative clustering (bottom-up) starts with each data point as its own cluster and then gradually merges them into larger clusters based on similarity.
Divisive clustering (top-down) begins with all the data as one big cluster and then splits it into smaller ones.
In agglomerative clustering, every data point starts as its own separate cluster. Then, clusters are merged step by step based on how similar they are until everything is in one big cluster.
The merging process follows a "linkage criterion," which could be based on the minimum distance, maximum distance, or average distance between the clusters.
My New Skill Boosting eBooks
I’ve put in a ton of work to bring you two powerful eBooks that make learning data analytics simple and practical. This is for all you guys, my readers!

📘 The Data Analytics Playbook – A step-by-step guide that takes you from beginner to confident data analyst. No fluff, just real-world examples, hands-on Python code, and everything you need to actually use data analytics.
📗 SQL Meets Python – Learn how to combine SQL and Python to handle real-world data projects with ease. Whether you’re querying databases or automating analysis, this book makes it easy to connect the two and get results fast.
Both books are packed with practical lessons and real examples—so you can skip the frustration and start building real skills.
Grab your copies today to boost your skills and your careers! Thank you for all your love and support in this journey.
If you’d like to read more about Hierarchical Clustering and Dimensionality Reduction (PCA) with a code breakdown the check out the full article below ⤵️

Conclusion
Alright, to wrap things up—this article gave us a good look into Clustering from unsupervised learning, and hopefully made it feel a little less overwhelming.
When you break these ideas down step-by-step, they start to make a lot more sense. We focused mostly on clustering today, and talked about both K-Means and hierarchical clustering. The big idea is that these methods help you find patterns in your data—even when you don’t have any labels to guide you.
The point here is to show that learning something big, like machine learning, doesn’t have to happen all at once. Taking small steps is usually the best way to really understand this stuff and build confidence along the way.
If you're new to this or just trying to sharpen your skills, I appreciate you being here. If you liked what you read and want the full, detailed breakdowns—along with extra code examples and real-world projects—be sure to check out the premium version.
It really helps support what I do and keeps The Nerd Nook alive.
Hope you all have an amazing week nerds ~ Josh (Chief Nerd Officer 🤓)
👉 If you get value from this article, please help me out, leave it a ❤️, and share this article to others. This helps more people discover this newsletter! Thank you so much!