



Why Feature Engineering is the Secret to Supercharging Your Machine Learning Models
Learn how feature engineering can transform raw data into powerful insights, boosting your machine learning models for better predictions and performance.

Machine learning models are only as good as the data they learn from. But raw data, really?
It’s usually a mess—full of gaps, inconsistencies, and extra information that doesn’t really help. If you throw that kind of data into a model as-is, don’t expect it to magically figure out important patterns on its own.
That’s where feature engineering comes in and what we’ll be looking at here in our weekly article.
Feature engineering is all about reshaping raw data to make it more useful. It means creating new features, improving the ones you already have, and uncovering patterns that might not be obvious at first glance. Even the most powerful machine learning algorithms can struggle if they don’t have the right features to work with.

Each week, I dive deep into Python and beyond, breaking it down into bite-sized pieces. While everyone else gets just a taste, my premium readers get the whole feast! Don't miss out on the full experience – join us today!
In this article, I’ll break down why feature engineering is so important, how to create better features from your data, and how techniques like scaling and transformation can make a big difference in model performance.
This article is only a slither of my Machine Learning series. If you are interested in taking your skills to new heights and learning ML to use in your career check out my new Machine Learning series here.
For my weekly free articles I try to spend some time mixing up the introduction for you guys, but as many of you know the actual content from these articles are segments from my weekly long-form articles.
These are mean’t to be a stepping stone but also a taste of my premium content. I always link the full article at the bottom for you. The long form articles go into more detail, have more code examples and tips you can use.
If you haven’t subscribed to my premium content yet, you should definitely check it out. You unlock exclusive access to all of these articles and all the code that comes with them, so you can follow along!
Plus, you’ll get access to so much more, like monthly Python projects, in-depth weekly articles, the '3 Randoms' series, and my complete archive!
I spend a lot of my week on these articles, so if you find it valuable, consider joining premium. It really helps me keep going and lets me know you’re getting something out of my work!
👉 Thank you for allowing me to do work that I find meaningful. This is my full-time job so I hope you will support my work.
If you’re already a premium reader, thank you from the bottom of my heart! You can leave feedback and recommend topics and projects at the bottom of all my articles.
👉 If you get value from this article, please help me out, leave it a ❤️, and share it with others who would enjoy this. Thank you so much!
Why Feature Engineering Matters
We know by now that raw data usually isn’t perfect for machine learning. It’s often messy, has extra information that’s not useful, or missing important details that could help with predictions.
That’s where feature engineering comes in. It’s the process of creating new features from existing ones to give the model better insights.
If we think about an e-commerce dataset, maybe we have a column called "purchase_date." By itself, it doesn’t tell us much. But we can turn it into new features like:
Day of the week (Are people shopping more on weekends?)
Hour of the day (Do most purchases happen in the evening?)
Season (Are sales higher during holidays?)
Wow, bam! Now when we take a step back and look at these extra details, they give the model valuable context it wouldn’t figure out on its own, leading to better predictions.
Turning Raw Data into Useful Information
Feature engineering is all about pulling useful insights from raw data. Let’s say we have a dataset with timestamps, transaction amounts, and customer IDs. A machine learning model won’t just "see" patterns on its own—you have to create features that highlight important trends.
Creating New Features: Finding Hidden Patterns
Let’s say you're working with that e-commerce dataset I just mentioned and you want to predict customer purchases. Instead of just using raw timestamps and purchase amounts, you can now create new features like:
Time-Based Features – What hour was the purchase made? What day of the week? Was it a weekend?
Customer Behavior Features – How many purchases has this customer made in the past month? What’s their average spending per transaction? How often do they shop?
Interaction Features – Combining different pieces of data, like the ratio of high-value purchases to total purchases, to uncover new insights.
All of these now add even more data to your dataset. With all this new data we created from the existing data we are allowing our model to become even more accurate. Now let’s check out an example to extract time-based features:
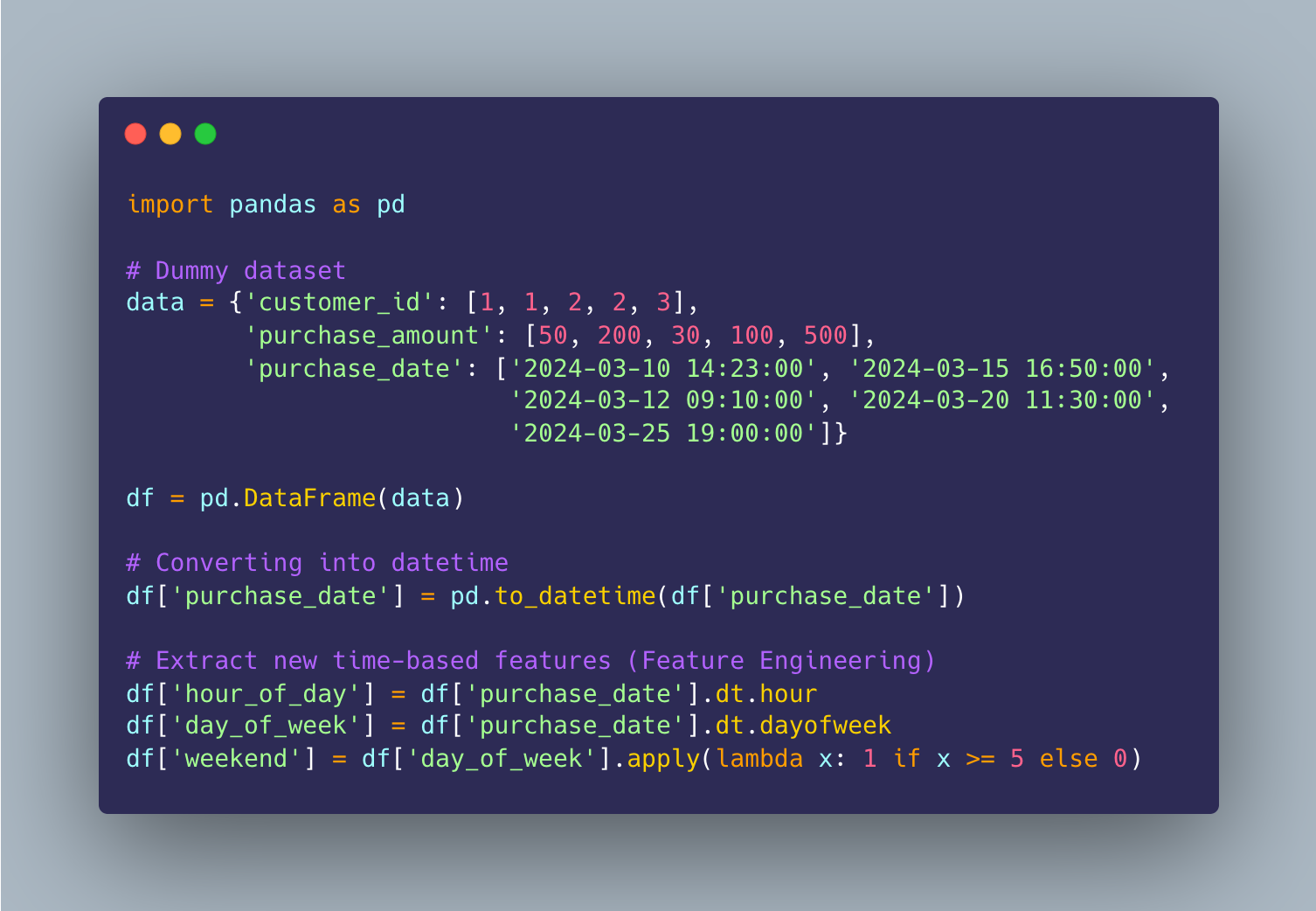
At the bottom of my code you can see that I built out some new columns int he dataset, this is really “feature engineering”. These new features will help the model recognize purchase patterns based on time and customer behavior:
hour_of_day – The hour the purchase happened
day_of_week – A number representing the day (0 = Monday, 6 = Sunday)
weekend – A simple flag (1 = weekend, 0 = weekday)
Pandas has a lot of built-in properties for converting our data into date and time formats. You can see in each of my new columns I tapped into that to make the conversion.
By transforming raw timestamps into these structured features, we give the model more useful information to improve predictions.
👉 If you get value from this article, please help me out, leave it a ❤️, and share it with others who would enjoy this. (Premium Readers get ad free content) Thank you so much!
Stop Struggling—Master Python the Fast & Easy Way!
Most people waste months bouncing between tutorials and still feel lost. That won’t happen to you.
👉 I’m giving you my exact system that’s been proven and tested by over 1,500 students.
My Python Masterclass gives you a clear roadmap, hands-on practice, and expert support—so you can master Python faster and with confidence.
Here’s What You Get:
✅ 135+ step-by-step lessons that make learning easy
✅ Live Q&A & 1-on-1 coaching (limited spots!)
✅ A private community so you’re never stuck
✅ Interactive tests & study guides to keep you on track
No more wasted time. No more confusion. Just real progress.
Enrollment is open—secure your spot today!
P.S - Save over 20% with the Code: PremiumNerd20
Making Data More Useful with Feature Transformation
Sometimes, instead of creating new features, we just need to adjust the existing ones to make them work better for machine learning. There are a few ways we can go about this based on what we want to achieve with our model.
But let’s first take a look at some of the most common ways we can do this:
Scaling & Normalization – Adjusting numerical values so they’re within a consistent range.
Log Transformation – Reducing skewness in data that has extreme values.
One-Hot Encoding – Converting categories into numbers so models can understand them.
Why Scaling Matters in Machine Learning
When working with machine learning models, one crucial step that often gets overlooked is scaling your numerical data. But why does it matter so much?
Imagine you're building a model that predicts customer behavior based on different features like age and income. Age typically ranges from 0 to 100, while income might range from $30,000 to $500,000.
If you feed these raw numbers into a machine learning algorithm without adjusting them, the model might treat income as far more important than age, simply because it has larger values.
This becomes a serious issue for models that rely on distance-based calculations, such as K-Nearest Neighbors (KNN)and Support Vector Machines (SVM). These models measure how close or far apart data points are, so if one feature has much larger numbers than another, it can dominate the calculations and skew the results.
By scaling your data—using techniques like standardization (z-score normalization) or min-max scaling—you ensure that all features contribute equally, leading to more accurate predictions and better model performance.
Skipping this step can make your model biased, less reliable, and even ineffective in real-world applications. So, before training your machine learning model, always check if your numerical data needs scaling. It’s a small step that can make a huge difference.
👉 If you get value from this article, please help me out, leave it a ❤️, and share it with others who would enjoy this. (Premium Readers get ad free content) Thank you so much!
My New Skill Boosting eBooks
I’ve put in a ton of work to bring you two powerful eBooks that make learning data analytics simple and practical. This is for all you guys, my readers!

📘 The Data Analytics Playbook – A step-by-step guide that takes you from beginner to confident data analyst. No fluff, just real-world examples, hands-on Python code, and everything you need to actually use data analytics.
📗 SQL Meets Python – Learn how to combine SQL and Python to handle real-world data projects with ease. Whether you’re querying databases or automating analysis, this book makes it easy to connect the two and get results fast.
Both books are packed with practical lessons and real examples—so you can skip the frustration and start building real skills.
Grab your copies today to boost your skills and your careers! Thank you for all your love and support in this journey.
Continue reading the article below for more on Feature Engineering and Selection below ⤵️

Conclusion
Feature engineering is a crucial part of building a solid machine learning model. Just feeding raw data into a model won’t cut it—it needs to be cleaned up, adjusted, and organized so the model can find meaningful patterns.
By creating new features, tweaking the ones you already have, and using methods like scaling and transformation, you're setting your model up to make more accurate predictions.
If you skip this step, you could be missing out on valuable insights, which can hurt your model’s performance. But with the right feature engineering, you can turn messy, unorganized data into powerful information that helps your model perform better.
So, before you start training your next model, take a moment to think: Are you giving it the best data to work with?
Hope you all have an amazing week nerds ~ Josh
👉 If you get value from this article, please help me out, leave it a ❤️, and share this article to others. This helps more people discover this newsletter! Thank you so much!